

What it is and why it matters
Introduction
Machine Learning allows computers to discover underlying patterns in data without human intervention or explicit programming instructions.
For simple tasks, a programmer can write the code, and the computer executes the task prescribed by the program. For complex tasks and large datasets, it is possible to let the machine develop its own solution to a problem, where humans would find it impossible to write the level of detail to handle all of the possible scenarios the task could require. Machine Learning models leverage computational power to have the capability to process vast data sets in real-time, resulting in an analysis that sometimes is beyond human capability.
A Brief Machine Learning History
Early Machine Learning
ML began in the 1950s as part of Artificial Intelligence (AI) and the interest in having machines that could learn from data, starting with a few simple algorithms. Interest continued in the 1960s and 1970s with work focusing on pattern classification, and over the decades, ML diverged from the classical AI goal of machines that can mimic (at least) human intelligence. Instead, by the 1990s ML had gained popularity as a way of solving practical problems with a data-driven approach. As ML began to be seen as its own field of research, more advanced algorithms were developed, personal computers became a practical reality, and commercialization of ML began to appear in games, business, and functional applications.
Why now?
In the 5 years between 2012 to 2017, machine learning jobs grew ten-fold, with data science growing more than half in the same period. In the last decade, the amount of data available has increased exponentially, with current data output estimated at nearly 3 quintillion bytes daily. For reference, 1 quintillion bytes is approximately 1 exabyte (exa = multiplying by 1000^6) which is approximately 250,000 Billion pages of text.
Even if only a small percentage of the data is accessible or potentially useful, the volume demands the most powerful and efficient toolset to analyze. Concurrently, data-driven decision-making emerged as the logic of choice, as the financial gains from decisions based on accurate information–and predictions–were powerful motivators for competing businesses to use the most efficient tools within their reach.
Fortunately, as data velocity, variety, and volume (the 3Vs) exploded, the infrastructure that helped facilitate it could also be used to analyze it: high-speed internet and network distribution, cheap and reliable storage, and computer processing power. And while traditional analytics was widely used, ML proved to be a perfect fit for addressing the scale, complexity, and ambiguity inherent in Big Data.
What is Machine Learning?
The Concept
Like other analytical tools, ML is used to transform data into knowledge. However, rather than scouring vast amounts of data to uncover an insight exposed in patterns and combinations of data through sheer processing power, Machine Learning not only looks for patterns, but also aims to identify the rules that seem to govern the data, applies that learning to the query, and provides a model that can then be applied to other datasets. In order to identify these rules, the algorithms in the ML model must learn from the inputs and their statistical distributions. Hence, the toolset is called Machine Learning. During this learning process, the algorithm(s) learn through a mathematical expression that represents the practical problem, refining the knowledge and learning what outputs are created under specific conditions. Through repetition with increasingly large sets of data, the ML algorithm is able to define outputs for new inputs, creating correct answers for new data–and usable information and insights an analyst could not achieve alone.
How does Machine Learning work?
As one would expect, an analytical process involving vast datasets, begins with gathering and preparing the data, and ends with some form of evaluation. The ML process follows this analytical model, but with several key differences.
- Data collection: Identify and gather all the data the algorithm will need to learn from and evaluate. Remember: most algorithms need large quantities of data to function accurately and increase generalization capacity.
- Data preparation: Clean, organize, and format the data into an accessible form, perform feature selection, feature engineering, etc. Bad data (labeling mistakes, inconsistent formatting, unstructured data in structured fields, etc.), missing data, and unclear features can all affect algorithm performance.
- Training: A training dataset for supervised learning will be exposed so that the algorithm learns underlying rules for mapping inputs to outputs.
- Testing: The model is tested against a holdout dataset to measure its performance and how well it learned. Note: In many cases, ML engineers will try multiple algorithms, thoroughly optimizing, and testing each to determine which performs best (model selection). It is not unusual to use multiple approaches to reach optimal results.
- Production: Testing and further tuning is performed after the model is put into production.
The process steps above are limited to those required to prepare an ML model for a general ML project. Real-world ML projects start with the problem identification, matching the problem to a potential ML solution, and ends with deployment and monitoring of the model for the target dataset.
Types of Machine Learning
Machine Learning can be grouped into different forms based on their method of learning: supervised, unsupervised, semi-supervised, and reinforcement learning.
Supervised Machine Learning
In Supervised ML, the goal is to learn the rules that define the relationship between inputs and outputs. The training dataset contains labeled outputs in order for the model to learn the relationships between the two. After learning, the model can then take new inputs, and calculate outputs based on the rules learned.
Supervised Learning uses training data of inputs and outputs to predict outputs based on new inputs.
Unsupervised Machine Learning
In Unsupervised ML, the algorithm is provided only input data–there is no labeled output data with which to compare the input. As one would expect, unsupervised learning excels in exploratory analysis when expectations are much less defined. Example models include Clustering (creating groups of similar features and attributes) and Dimension Reduction (removing data columns and uninformative features).
Unsupervised Learning analyzes data characteristics and uses these characteristics to create clusters of items with similar attributes.
Semi-supervised Machine Learning
As the name suggests, Semi-supervised ML is a mix of the above two approaches, with only some of the data including outputs. Since one of the challenges with Supervised ML is gathering the required large volume of labeled input/output training data, this mixed approach allows analysis and learning with a smaller set of labeled data, mixed with a much larger set of unlabeled data.
Reinforcement Learning
Less common, and more recent than the above model groups, Reinforcement Learning uses rewards instead of labels for learning. Algorithms in Reinforced Learning functions to increase rewards as it analyzes and learns from the data. Given a complex dataset with a defined reward, the algorithm optimizes to increase the reward so that it learns the optimal computation that provides the reward-based result.
Note, while each of these categories of “learning types” approaches learning and problem-solving differently, or at least to some degree, they all follow a core process theory: using mathematical computational models to find patterns, rules, and insights in large volume data, that are subsequently used by the practitioner to help solve a problem.
Advantages and Disadvantages of Machine Learning
Advantages
An obvious feature of ML is the ability to handle large and diverse data volumes with speed and accuracy. As targeted data volumes continue to grow, the applied ML scales without diminishing performance. The data can be extremely heterogeneous, with mixtures of structured/unstructured, multiple varieties (images, text, financials, voice), as well as multi-dimensional data with complex relationships across data features. Speed and accuracy outperform non-ML analytical solutions at scale.
As the data changes, ML adapts without human involvement. The most commonly cited examples include weather forecasting and computer virus detection–in both cases, ML adapts to compute the accurate output of new combinations of weather indicators and can identify new viruses when they appear in the technology ecosystem. The autonomous adaptability to change is partly a subset of automation, which is itself a valued feature of ML.
Because ML identifies trends, patterns, and insights that an unassisted analyst would never observe, the performance gains over non-assisted analytics is nearly immeasurable. The ability to apply in a wide range of fields has proven value across an expansive and expanding set of performance indicators–evaluating credit risks, flagging fraudulent transitions, autonomous robotics, debugging complex computer science programs, and many other fields in which failure is costly or dangerous. Finally, as ML models continue iterations upon even more data, the model’s performance efficiently improves its predictive capacity.
Disadvantages
Ironically, one of the primary advantages of ML can be a disadvantage–its use for large volume datasets in some applications. Because ML requires vast datasets of usable quality to train the model, access to such datasets can be a roadblock at the industry or specific domain level. Legal, privacy, and even proprietary knowledge can prohibit the gathering of appropriate data.
Large, sophisticated analytics projects with multiple technologies and content domains bring with them increased opportunity for error. Inexperienced practitioners deciding to conduct ML in-house may find that the susceptibility to huge errors in predictions based on something as fundamental as an improperly prepared data training set, or misinterpreting the output of an algorithm. Many ML projects are large-scale initiatives, spanning across multiple fields of control in the business (and even outside the business). The complexity of multiple large datasets in different locations with different owners and stakeholders can be tricky to navigate, especially for a long-term project.
Applied Machine Learning
ML Problem Groups
In Machine Learning, a model is an algorithm that has been applied and trained towards a specific problem type. It undergoes further learning when applied against a specific dataset to learn the unique patterns and rules that help to refine and present solutions for the practitioner.
Classification
Classification problems generally use supervised learning to predict a class value, e.g., whether a customer is in class “high-value” or “low-value.” While the output can be binary, classification can include multiple classes. At its simplest, classification models predict one of two classes, one of two or more classes, and in advanced algorithms, predicting multiple classes from among even more classes. While at the simplest level the model will identify whether a customer belongs to the high-value segment or the low-value segment, classification can, in fact, delineate customers across numerous segments. As expected, an apparently simple model like logistic regression can solve many classification problems: based on the training of labeled inputs and outputs, the logistic regression algorithm will assign a probability to the customer between 0 and 1, with 1 being a definitely high-value, and 0 being a definitely low-value customer. For non-binary classification, a customer (or another classification subject) is classified as belonging to one of a great number of classes, requiring a non-linear algorithm that predicts a probability distribution across them.
Regression
Regression models are supervised learning methods that predict the numerical dependent value given a particular independent value. In short, it finds the relationship between input and output and calculates it as a numerical value.
Clustering
A popularly used unsupervised model, clustering has a simple goal of grouping or clustering examples based on similar characteristics. Without labeled output data for training, clustering algorithms often use groupings instead. This automated grouping is recomputed repeatedly to refine an expanding number of clusters. For example, the K-Means algorithm randomly creates “K centers” in the data, then assigns other data points to the closest center, then recomputes the center of each cluster. This process is continued until the centers no longer change (or change very little). At this point, the process is complete. Clustering is effective and commonly used for customer segmentation.
Dimensionality Reduction
Both supervised and unsupervised algorithm models can be used for dimensionality reduction, also called dimension reduction, a process that removes the least important information (or dimensions) from the dataset. In extremely large datasets, such as digital image analysis, millions of pixels could be involved. Removing those pixels that are least important to the image analysis reduces the number to a less unwieldy dataset. Similarly, in large-scale marketing datasets like customer communications on blogs, social media, and customer service interactions, many of the dimensions captured from the various data sources may add little relevance to the research question. However, the more dimensions or features included in a model, the more data volume is needed for accuracy. Hence, analysts and researchers try to limit these uninformative features using a dimensionality reduction process before beginning their targeted ML-assisted analysis. Fortunately, in using algorithms such as Principal Component Analysis (PCA), the analyst can measure how much information is lost as a result of the reduction, and adjust before proceeding.
Natural Language Processing
Natural Language Processing (NLP) is less an ML algorithm than it is a technique that crosses the boundaries of linguistics, computer science, and artificial intelligence. In the context of ML, NLP is used as a precursor to ML-assisted problem-solving, by preparing the dataset (text or voice) for ML tasks.
Because the vast majority of data is in a human language, the value of NLP is in making these datasets understandable and valuable in a computer-enabled environment. As noted below in the Marketing Applications, ML models can use NLP processed text to examine vast volumes of customer produced data to identify patterns and rules in social media feeds, posts, and interactions on product websites, blogs, customer service forums/chat, and more. Whether it is using the ML-NLP model for sentiment analysis that informs customer and product alignment, or to surface unknown indicators of churn (the rate of customer attrition) propensity to reverse, analysts experienced with the toolset can uncover tremendous value using ML models on now-accessible human language datasets in all its forms.
ML-Driven Marketing
Below is a sampling of popular models applied in marketing-related areas. Because models and the algorithms they are composed of are subject agnostic, the same models and algorithms are often used for completely different, and often adjacent areas. While the primary goal focus of applications below may be in one area, most of the applications of ML in marketing cross topic boundaries based simply on an organization’s focus. For example, many of the ML-marketing applications could be called personalization (each personalized for a different purpose). Similarly, many could roll up to customer engagement; however, in the examples below, the most obvious marketing goal differentiator is used to illustrate disparate ways in which ML can be applied to impact performance and, ultimately, revenue.
Personalization
One might think of Netflix as being the poster child for Recommendation Engines. While certainly beginning by recommending movies and tv shows, Netflix quickly moved on to personalize everything in the equation. As part of their goal to increase screen time per subscriber, and to ensure new additions to their lineup receive clicks, Netflix used multi-armed bandit methods to determine the best visual for each new original movie or series. However, they then decided to serve custom visuals for each customer, so that the personalization of offerings included the enticement to try new offerings. Netflix uses ML algorithms to personalize the structure of rows of offerings on a viewer’s homepage, which graphics are used, the messages presented. Now Netflix engineers are looking to identify contextual variables that allow greater customization and more accurate recommendations. For Netflix, personalization means more screen time, which translates to renewed subscriptions and revenue.
ML-powered segmentation
Segmenting customers can be one of the core first steps toward personalizing the delivery of products, services, and messaging. Opening the dataset to include prospects as well as customers can quickly lead to an unwieldy volume of data to categorize against a list of indicators, many of which are still unknown. Using an unsupervised ML model such as Clustering (e.g., the K-means algorithm), practitioners can analyze billions of customer interest variables found in queries, social media interactions, product website touchpoints, etc. The result will be customer segmentation based on insights beyond the abilities of the best, unassisted analysts. ML-powered segmentation can identify the most profitable segments, customers most at risk of churn, products aligned with different segments, and even new product appetite.
Remember, the most profitable customer segment is based on Lifetime Value (LTV), not initial purchases, or even purchases to date. ML can predict LTV with greater accuracy and speed than traditional data analytics using a supervised learning algorithm that learns from historical data and predicts future outputs. Segmentation based on LTV is one of many examples in which a combination of algorithms and even model types are required to extract insights from a complex dataset.
Predicting customer behavior
Predictive analytics has been a powerful tool since government began experimenting with early computers in the 1940s, while others speculate it goes back to at least the 17th Century when Lloyds of London needed future estimates vital to the insurance business. In marketing, one high-value predictor is customer churn. Since a significant percentage of revenue is the result of repeat customers, predicting and addressing customer churn in advance is a significant revenue driver. Using ML algorithms that identify customers most likely to churn within a specific time period, businesses can intervene with messaging, incentives, and targeted offers to at-risk customers. While traditional analytics can segment customers into periods of inactivity, ML can surface and quantify numerous variables and signals of customer behavior prior to churn and can categorize levels of risk that prioritizes action.
Because many of the well-known indicators of the propensity for churn are lagging indicators, much of the damage has been done and the customer is nearly lost when identified. Therefore, the ML challenge is to not only identify customers likely to leave but to identify unusual behavioral indicators as early as possible. The first task can be resolved best with a Classification model (churn = 1 or 0), but the second requires anomaly detection. Anomaly detection requires the identification of relevant outliers and can be addressed with an unsupervised Anomaly Detection model.
Content creation and optimization
AI and ML specifically are able to impact content development and delivery at multiple points in the content cycle. Evaluating new research topics against customer segments, optimizing existing content for search engine performance and customer alignment, and even identifying priority content gaps.
For example, GPT-3, OpenAI’s language generator can automatically create shorter content pieces based on structured data, automating the development of product descriptions, tweets, customer marketing emails, short news reports, all in less than a second.
Using NLP to generate insights
As indicated in one of the sections above, NLP is a sub-field that crosses linguistic, computer science, and artificial intelligence boundaries. NLP techniques can be used to parse through language-based content, whether voice-based or textual, and create usable datasets that can then be parsed based on a multitude of variables, such as sentiment, which provide valuable insights into customers’ feedback on products, relevant trends, and measurable churn risk. These data-based insights embedded in thousands of customer posts and interactions across multiple channels can, again, lead to product improvement, churn reduction, new (customer-desired) products, and services, and, ultimately, conversions.
The same approach can be used to assess all news sources to derive insights from similar variables, gathering actionable knowledge from online news sources and blogs addressing the relevant industry and specific business.
Customer engagement
One of the more popular ML applications currently is the use of chatbots to improve customer service–eliminating wait times, always “live”, connecting to up-to-date product information and help desk answers–all while building an ever-expanding dataset at the product and customer level through capturing queries, responses, and threads.
While many customer service bots are more scripted than AI-enabled, those that are using NLP and ML are able to provide advanced functionality to rival the customer experience of live chat. An ML-enabled chatbot can adapt as more questions are processed, are connected to all of the online resources relevant to the topic, and are able to capture and escalate to live customer service reps if necessary.
Marketing automation
When Marketing Automation platforms began to take off in the 1990s, it began by taking advantage of the flurry of technological advances present in CRM and Email Marketing programs crowding the market. The key functionalities, automating repetitive and somewhat simple tasks, were quickly augmented with other more complex tasks–tasks driven by Machine Learning. Using ML to process a mass of captured customer data the automation platforms began to power intelligent decision-making with automated Lead Scoring and personalized customer development along the entire customer journey. Insights extracted from captured interaction data could be used to dynamically serve each individual with accurate messaging at each point, transforming prospects to lifelong advocates.
Optimized advertising
Many of today’s ad platforms have integrated AI and ML technology to allow marketers and advertisers to reach more prospects with less work. Much of the automated optimization can replace significant manual work when creating an advertising campaign, and optimize the performance simultaneously. Using Google Ads’ Smart Bidding takes much of the manual (informed) guesswork out of the process. Rather than determining what the optimum PPC is for a targeted keyword, advertisers can instead plug in the highest acquisition cost relevant to the model. As long as the business knows what a lead or acquisition is worth, Google’s ML will use millions of signals to calculate which ad to serve, when to serve it, what to bid–all in milliseconds, and all more effective than most manual bidders.
Similarly, Facebook’s Lookalike Audiences feature allows marketers to capture prospects who match currently converting customers by creating an audience that matches profile elements of the previous converters–signals and data elements that indicate various interests and demographics that are shared by the target audience.
Social media management
With literally billions of active users, social media has grown as the center of new marketing efforts. Social media management is a requirement for any business with a presence, responding to critical reviews or complaints, maintaining trend awareness, and mining the wealth of direct customer data posted each day. Marketing departments dipping into the Twitterverse or Facebook world for the first time may be overwhelmed by the resources required to monitor, much less respond to, critical issues. Fortunately, multiple models are available to not only assist in management practices but also outperform humans in extracting value from an organization’s social media footprint. Using ML to identify key posts in real-time ensures no opportunity is missed, and no negatives have an opportunity to grow into trends. Because ML is perfectly suited for Big Data’s 3Vs (Volume, Velocity, Variety), it is an excellent tool for “listening” to social media feeds and not only separating the wheat from the chaff but also identifying neglected or new opportunities (e.g, keywords, audiences), trends recognizable only if simultaneously viewing multiple social media feeds and being alert to trends that demand 24/7 attention to megabytes of data. Today, ML models can isolate sentiment, specific demographics, interests–if it can be expressed with language, it can be analyzed.
Website SEO at scale
Thanks to years of knowledge sharing from SEO practitioners, SEO analysis, and on- and off-page practices can be addressed using new technology. As a result of this work, numerous tools now use ML to automate some processes, tracking hundreds of ranking indicators and identifying which variables—tags, metadata, page types–should be modified to increase the visibility, ranking, and overall success of web-enabled businesses. Even preparation for voice search, a quickly rising percentage of queries, uses ML for optimizing a website for the most successful voice search queries. Using the available tools that integrate AI and ML into their engines provides a significant boost to SEO practices and corresponding results. For example, Arcalea's Compass AI SEO platform tracks millions of data points to identify the most important ranking factors.

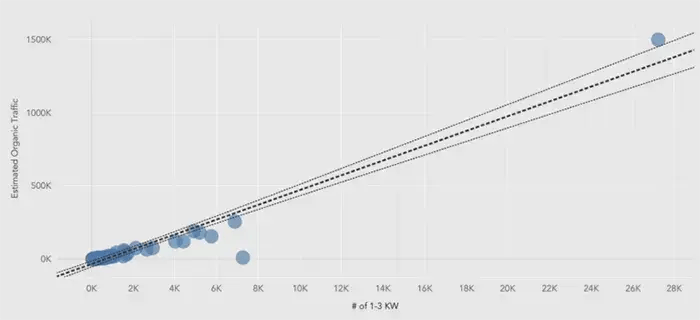
Machine Learning in Organic Search
Using a Machine Learning Framework for Search Engine Predictive Modeling Overview The interactions between market ...
Recommendation engines
Almost anyone shopping online or streaming entertainment has made decisions based on a recommendation engine. Netflix depends on these algorithms to curate recommendations for viewers, Amazon used the technology as a key differentiator when it began and gains significant revenue from it now, and Spotify’s recommendation engine is a core part of its model. The benefits to online businesses go beyond the personalization now expected by savvy customers. Engines that use customer-specific data to curate offerings in real or nearly real-time are constantly improving their customer “fit”–the more a customer interacts, the more closely the business tailors the suggestions, offerings, deals, and experience. Such constantly improving customer alignment and overall UX drives retention. Of course, e-commerce businesses drive significant revenue when able to accurately identify interests and match the customer to the product. In the latest published figures (2013), Amazon was realizing 35% of its revenue from recommended products.
The two main types of recommendation systems are collaborative filtering and content-based filtering. With collaborative filtering, companies compare the viewing or purchasing habits of customers with similar profiles to make recommendations. While popularized by Amazon, many companies now offer “Customers who viewed/purchased this . . .” recommendations during a product search or after adding to a cart or watchlist. Data from purchases, demographics, and even 3rd party data can be combined to create a persona that then receives the recommendations across the persona set. Content-based recommendations are tied to specific customer purchases and views, and likely includes other customer-attributes such as product reviews, likes, and ratings.
Recommendation systems are powerful opportunities to increase customer experience value, drive service satisfaction, and drive revenue. The ML models enabling these systems include algorithms that process large volumes of text prepared with NLP, Cluster models that plot the most critical variables of customer profiles and products chosen, as well as Classification models performing sentiment analysis related to the choices.
Adopting Machine Learning
Requirements
The core requirements for implementing ML systems are common to any ML project; however, depending on the specific characteristics of the investigation, additional components could be required. For example, for analysis of large-scale customer comments, an NLP engine would be essential.
- Data: Large datasets relevant to customers, products, and services, and relevant to the line of inquiry
- Models: ML models that match high priority problems (Classification, Clustering, Regression, etc.), many of which are freely available. The libraries and dependencies required should also be prepared depending on the programming languages used by the team and the technology stack. Some ML Engineers will use a simple text editor for simple coding and model building but these changes depending on the analytics maturity of the company.
- Skills: Applied mathematics, working knowledge of algorithms, and ML modeling. Depending on the role, resources typically need to be highly proficient in one or two programming languages, as well as have database experience; virtual machines and cloud environments; utilities like Hadoop for distributed processing; statistics and validation.
- Environment: an environment suited for conducting ML projects. While a workstation is sufficient for many of the early research and planning (identifying datasets, defining preparation, choosing models), larger tests can take days to complete, and require more processor power and memory than a workstation. If local server bandwidth is not available, working environments can be “rented” from cloud-based vendors like AWS (which also supplies various ML models like recommendation engines, text extractors, and image recognition, etc.).
Defining a Use Case
At the outset of ML project consideration, defined company strategic goals should identify areas of investigation that are well-suited for ML-assisted inquiry. Once the senior team narrows and prioritizes goals most likely aligned with an ML solution (large dataset, targeted investigative area relevant to the dataset), the ML Engineer for the project must match the problem with the solution–the ML model or models best aligned with the solution.
Fortunately, a large body of practice now exists as a resource to compare with the current proposed research area. As a result, most likely multiple models will surface as likely solution candidates. The solution could be the use of one model and a corresponding algorithm that drives it, or multiple algorithms in one model category, or even a sequential set of models for a multi-step solution or even an ensemble method. Creating a solution design capturing the approach ensures the project is scoped for platform and data resources, model and testing requirements, and personnel roles, and likely project timeline.
Defining the solution sets clear expectations, and allows the methodical planning and step-building to take the project from data preparation through training, testing, and deploying.
Future Trends in Machine Learning and Marketing
Machine Learning will continue to expand and improve, continuing the trend line of the past decade with currently unique techniques becoming standardized (Deep Learning, Dynamic Environments), but some specific shifts are likely to influence the way marketers use ML.
Sentiment Analysis to Sentiment Encoding
Recent Google experimentation has highlighted a couple of high-value future potentials of ML that have had fewer successes in the past. After gathering data from over 40 countries, Google applied advanced ML to each step in the funnel for experimenting with NLP to not only analyze the sentiment of messaging but to generate new sentiment-carrying messaging to tie targeted positive emotional attributes and empathy to components of campaigns. Results exceeded the group, in some cases doubling conversions. Applying the same techniques to landing page optimization found similar performance increases, which could be measured at the page component level.
Long Cycle Forecasting
Predictive analytics and forecasting are traditionally difficult to match with the longer B2B cycles, often taking as long as 6 months between sign-up and adoption of services. Google focused its ML system on learning historical data tied to the long-term value of an ad click and was able to predict solution adoption 3 months out.
Packaged ML Solutions
Off the shelf, solutions are transitioning much faster from first practice emergence to packaged monetization. In the last few years, the number and variety of specialized ML widgets and apps have proliferated as practitioners realized the value of reusable models to small businesses–and even mid-sized businesses with limited analytics resources. Various sites list ML apps available, and others list ideas for ML-assisted apps that are in high demand for developers.
While doubtless many new approaches will offer value in the next 5 years, but given the current capabilities that are underutilized, most businesses will benefit greatly by fully exploiting the ML-assisted analytics tools currently accessible and aligned with their mission.
Machine Learning as a Key Growth Factor
As illustrated in the ML marketing applications above, the insights uniquely available through an ML strategy allow businesses to not only compete, but to stay ahead of the curve by picking up customer, product, and industry trends as they are developing, solving complex problems before they fully materialize, and predicting future value with sophisticated analytics available only through ML-assisted queries of large-scale data. The ML systems, while continuously expanding in versatility and impact, are part of a mature data science model.
The underlying driver most indicative of success is likely a company’s current state of integrated analytics. Organizations that have reached a moderate level of data maturity will have few problems adding ML practices into their data analytics ecosystem. These organizations are actively using data platforms (CRM, CDP, etc.), transforming data into insights and shareable visualizations of future-focused business practices.
Organizations that continuously invest in customer analytics increase their competitive advantage, and are well-suited for ML and other AI-enabled performance multipliers. Businesses focused on improving analytic capability and performance should look to updating their toolset with today’s ML solutions–powerful, accessible, and proven.

Data Science Maturity Models (DSMMs): A Broad Consensus Composite
The majority of Data Science Maturity Models (DSMMs) reviewed cover 4-5 levels with outliers reaching 6 ...



RESPONSES