
Testing and Experimentation in the Digital Marketplace

The Rise of Digital Tests and Experiments
Even before the development of a ubiquitous digital ecosystem, growth-focused businesses performed tests and experiments aimed at many of the same areas of practice. Just as today, elements throughout the product life cycle were tested: product ideation (to determine if a product would find a market), prototypes (to test features and configuration preferences among consumers), ad creatives (to find “real world” consumer reactions), targeting (to maximize TAM penetration), and post-purchase (to measure consumer long-term satisfaction). Earlier, the dominant tools and practices were primarily analog, and often cumbersome in design, execution, and analysis: door-to-door canvassing, public polling, focus groups, telephone queries. Most demanded direct, intrusive contact with consumers and considerable time before researchers could compile and assess for actionable insights.
Digital Transformation
Today the available digital infrastructure allows businesses to experiment faster, at greater volume, with greater complexity, and stronger validation. With the reduction of cost barriers to accessing and using data, and the increasingly expansive application of data practices, digital data-driven business practices opened up–changing what could be done, and who could do it.
Instead of small sample in-person focus groups, digital service companies such as Netflix experimented with multiple targeted segments of consumers, used randomized control trials, flipped parameters at any moment, and monitored results and analytics in real time. When a profitable insight was realized, Netflix applied the modification instantly, often accurately predicting the corresponding revenue lift in advance.
“In an increasingly digital world, if you don’t do large-scale experimentation, in the long term—and in many industries the short term—you’re dead,” Mark Okerstrom, the CEO of Expedia Group
Digital Experiments and Marketing
One beneficiary of these digital advantages was marketing. With a life-cycle parallel to that of the business products and services, marketing adopted the medium advantages for researching, promoting and advertising, digital transactions, and testing or experimenting. Unsurprisingly, some of the most robust digital marketing experimentation platforms are coming from digital services giants, such as eBay, JD.com, and Booking.com. However, with cost-effective access, mid-size businesses are able to access plentiful relevant data and use scalable data platforms to store, aggregate, and analyze all components of the business. Even small businesses could access digital advertising platforms, create a sophisticated marketing mix, and ultimately, begin testing ad components to increase performance.
Valid business tests and experiments depend on the volume normally associated with large enterprises. Volume, however, is inherent to digital advertising, enabling any mid-level business access to tests and experiments that can lift performance and produce breakthroughs with even small initiatives.
Tests and Experiments
While “test” and “experiment” are often used interchangeably by brands and marketers, each has a set of defining characteristics that separate the practices, each following different processes, purposes, hypothesis types, outcome expectations.

Tests are generally more narrowly focused activity, with a common linear process, a clearer timeframe, budget, fixed methodology, and an expectation of a clear winner or tested assumption as a result. For example, marketers might conduct a simple A/B comparison of two digital advertising elements (e.g., landing pages), with one variant between the two. Or they could conduct a more complex simultaneous multivariate test, randomized across target audiences of specific volumes with the aid of an AI-powered 3rd party testing tool. While the latter test is more complex, if the goal is to confirm an assumption, and the expectation is that a clear outcome (“winner”) will result, the practice is closer to a test than an experiment.
Experiments tend to be more open and may attempt to “test” one or more hypotheses, but also seek to understand the ramifications for introducing change in an environment (e.g., multiple dimensions in landing pages), and follow open-ended “what if” questions. Experiments are akin to researching and hypothesizing; rather than confirming assumptions, experiments will qualify and quantify assumptions. A specific outcome is less expected; instead, a 90% failure rate is unsurprising. However, the realistic 10% chance of success–“something worth implementing”–may lead to a discovery of significant value. When MSN experimented with opening Hotmail in a new tab (rather than the same tab), engagement increased 8 times the rate of typical engagement changes.
A clear demarcation line between business test and experimentation practices may be difficult to isolate; however, the definitions are less important than being able to identify the type of test or experiment that fits a given need. Ultimately, both tests and experiments aim to create better customer experiences with product and services offerings, with customer service, with the digital footprint, and all points of customer interaction with the brand.
Both are essential. Testing is foundational. It validates assumptions, heads off unnecessary investment, optimizes existing interventions, initiatives, and their elements. Testing is accessible to smaller entrepreneurs and large brand leaders. It is efficiently implemented, and can validate lift from variants. Because of the targeted nature of testing, it can serve as a validation of recommendations arising from more complex experiments.
The Challenge of Variable Volume and Complexity
Digital marketing creates nearly infinite opportunities for tests and experiments from the volume and variety of possible variant combinations, with opportunity to optimize and create value. Brands can try new variants of existing ads and campaigns, compare variants of audience attributes and targeting parameters for a new product or offering launch, and probe more complex questions regarding performance across thousands of advertising variations and possibilities.
However, when thousands of options are readily available, determining which to test for greatest performance opportunity becomes a key challenge. With the increased accessibility of data, the challenge of gathering enough data becomes the challenge of how to interpret large volumes of data, or more specifically, how to select the most relevant data to analyze.
An online electronics store, Monitor St✩r, is preparing for an upcoming sale. The brand’s marketing team knows their key audiences’ concerns of price, quality, and stocked merchandise. For their display and search ads, the marketing team needs to identify the most effective headlines using multiple A/B tests with headlines alternating between “Match Lowest Price,” “Top Reviewed LED Monitors,” and “All Items in Stock.” Using randomized control A/B tests across validated sample sizes, they identify top performing combinations for the campaign to push to the full target audience.
The Underlying Data Infrastructure
While such A/B online ad variant tests are common, this simplified example obscures the work supporting it: researching the target customer segment, determining the question or hypothesis, capturing and assessing the data that lead to the question or hypothesis, the channel in which to test, the element of online advertising (OLA) on which to focus (e.g., extended text ad, display ad), the dimension of the OLA element (e.g., headline), the variants of the dimension to design/create (e.g., the three options), the metric that best measures the result (e.g., CTR), and the post-test data needed to analyze results.
Much of this work and many of the decisions may have occurred much earlier in the product offering cycle, or even earlier in the brand’s history. But the information that drove the parameters of (and reasons for) the test were captured, gathered, or in some way completed before the test could be coherently designed and executed.
These underlying data points, in part, make up the infrastructure that enables the test or experiment. In a broader sense, experimentation requires infrastructure that is built from ideation of product offering, through offering development, strategy for bringing the value to market, and post-sale customer advocacy. Without the supporting data informing the test, marketers would quickly be overwhelmed by the choices available to impact performance in a marketing campaign.
Testing is native to digital advertising. It’s happening continuously from ideation through advocacy.
Subset of Digital Ad Variants
Variable Volume and Complexity
Even a simple A/B test is predicated on the existence and understanding of the supporting infrastructure underlying all elements of the OLA being tested. The sheer volume of variables and variants is too large to intuitively design the test elements. Moreover, many tests and experiments are answering far more complex questions than which text ad variant performs the best. The entire customer journey provides opportunity for optimization and innovation. Choosing variances to investigate reveals the complexity in making the right choice. For example, if the brand is not receiving enough conversions to meet goals, where does the marketer begin?
The Granadian Garden, an online wholesaler of imported Spanish cuisine ingredients, is not receiving enough conversions to meet goals. In order to design tests, Granadian Garden’s marketers and analysts must narrow the question from “How do we increase conversions?” to a testable hypothesis.
They start by analyzing the data: What is the conversion rate? If the conversion rate (CR) is 1%, the question could be narrowed to focus on elements impacting conversion rate optimization (CRO), such as keywords, targeting, alignment between keywords-ads-landing pages. If the CR is 3% but not hitting conversion goals, the questions are pointed toward conversion rate volume (CRV): Is the audience big enough? Are we targeting the wrong audience? Depending on the direction the data points, Granadian Garden’s marketers check the corresponding underlying data. Is the original assessment of the Total Addressable Market (TAM) correct? Are the campaign’s targeting parameters aligned with the TAM attributes? Before these questions are answered, the marketing team cannot create the testable hypothesis and test design.
Scalability
As the number of variants expand to test hypotheses, the challenge of scale becomes more burdensome. Testing dozens of variants, whether through simple split tests of A/B or A/B/C/n, or even multivariate tests comparing combinations of variants, requires significant time to ensure each test addresses a valid volume of control and treatment segments,
Once a solution is identified, the better performing variants must be rolled out to the full target audiences. While new search ad text or a display ad image is simple to implement with most ad platforms, more complex variant sets do not scale as easily. If the experiment was to see how to better align messaging with specific targeted segments, it could use a dozen landing pages with different ads and even keywords in separate ad groups. Depending on the performance of the disparate combinations, rolling out to each full segment becomes more complicated and depends on an infrastructure to efficiently and accurately scale.
Biases
An easily hidden challenge, the introduction of bias into a test can invalidate test design or resulting data interpretation. When marketers conduct tests and experiments with insufficient underlying infrastructure to support the framework or validation, cognitive biases can introduce errors in test parameters and analysis. Marketers might focus on what confirms existing beliefs, see patterns when data doesn’t support them, or simplify probabilities to reduce the complexity of analysis. Some common biases below can skew or invalidate tests and experiments.
- Confirmation bias: subconsciously selecting information that confirms a desired truth while limiting the focus on contradictory data. This bias can influence researchers to select parameters for a test that aren’t aligned with the data or focus on results confirming beliefs and not what the data truly reveals. If a brand leader intuitively “knows” that a manual cost-per-click bidding strategy is best, he may omit tests for other bidding strategies, or ignore data that demonstrates that a bidding strategy of total cost per acquisition (TCPA) is the highest performing solution.
- Sunk-cost fallacy: maintaining a poor direction because of the resources already invested. A complex ad campaign requires time and money; when performance problems can’t be resolved with minor adjustments or an obvious A/B test, the sunk-cost fallacy can influence stakeholders to continue the campaign rather than conduct tests or experiments to determine what should be changed or discarded. Loss aversion bias similarly pushes marketers from a potential risk of a novel approach in favor of maintaining a poor performing one.
- Clustering illusion: finding unsupported “meaningful” patterns in random data. This bias can surface when tests and experiments include a large number of metrics, or the sample size is too small to be validated. Looking at enough data points (such as a dozen metrics) for a long enough duration, many people will begin to see patterns that are no more than noise introduced as a result of broad test parameters. This can combine with the Appeal to Probability bias if marketers use the small meaningless pattern as a foundation for other tests or marketing.
- Arrival rate bias: testing in which different subjects (in either control or treatment) respond at different speeds to the test. As a result, initial results are skewed. If the test is not extended to allow for heterogeneous return rates, the final dataset will not accurately reflect the results once the full target segment is participating.
- Additive bias: when researchers sequentially experimenting with multiple independent variances expect a cumulative lift not reflected in actual live performance of all variances at once. The additive lift represented by as few as two experiments may not coincide with cumulative live performance due to varied confidence levels in each experiment, disparate control/treatment data resulting from sequencing rather than simultaneous testing, and differences between short- and long-term effects across variants.
The challenges inherent in ad testing and experimenting can easily derail problem solving, optimization, and breakthroughs. While the obstacles present span the test process from narrowing the hypothesis to choosing variants and avoiding bias, the fundamental requirement underlying effective practices is a broad infrastructure supporting the design, execution, and measurement of tests and experiments.
How Infrastructure Powers Tests and Experiments
Determining the Hypothesis
Designing tests and experiments requires identifying the testable hypothesis, or target question. As the example of Granadian Garden demonstrates, determining and narrowing the key question requires data points that inform the variables of the marketing in question. If the goal is to increase conversion rate volume (CRV), marketers must review the campaign’s targeting data and parameters and the target market research that it is based on. If instead, the goal is conversion rate optimization (CRO), marketers must determine which domain is undermining performance: keywords, targeting (geo, attributes, temporal, etc.), message alignment, etc. Again, marketers need to review the current data and the precursors for each element, such as keyword research, market and customer analysis, and site infrastructure architecture (IA).
As the hypothesis is narrowed and focused, fewer tests are required to determine the solution. If data informing the current campaign elements are not available, the experimental net becomes wider as marketing now has to conduct multiple tests to narrow from the many domains and their respective dimensions.
With a conversion rate (CR) of 1%, Granadian Garden determined the goal is to increase conversion rate optimization (CRO). Their analysts reviewed the data underlying the different domains: the keyword research confirmed ranking keyword choices, the market analysis and research behind the customer persona was verified as still valid, but the alignment between messaging elements was not validated, nor was the current page-level information architecture (IA) assessed. They now have a clearer experiment focus: the landing pages.
Designing the Experiment
Before structuring the experiment, analysts first exclude as many variables as possible. For example, by using a web analytics platform, such as Google Analytics, they check traffic data for alignment with prior expectations: the volume and percent from different channels, which landing pages are entry points, comparative load times, devices. They might also check data from the ad platform, such as Google Ads, using impression share to verify opportunity is not lost to competitive ranking or spends.
Finally, the experiment is designed to answer the question: What combinations of landing page elements will perform the best?
After reviewing relevant data, Granadian Garden identifies the experiment steps to identify top performing landing pages to increase CR:
- Create new heat and scroll maps to learn visitor on-page behaviors for existing landing pages, and compare with competitor maps.
- Assess page-level information architecture (IA): hero image, above/below the fold item placement, value proposition, etc.
- Create variants of call to actions (CTAs), including phrasing, placement, format (button, text, color, etc.).
- Create variants of landing page layouts.
- Map ads and landing pages to divert valid segments to variants and track results.
If their existing infrastructure doesn’t currently support the experiment design, the brand must either create the components necessary, or risk experiment integrity by limiting the design to existing capabilities.
Measuring the Experiment
When the experiment duration is complete, the data from web analytics, ad platform, and CRM is aggregated into a primary analytics platform for clean-up, transformation, and visualization. Analysts identify visitor preferences, trends, and insights across landing page variants by drilling down into individual parameters in each option. For example, if landing pages 3, 7, and 9 were high performers, the characteristics of each are charted and examined for commonalities. If the average CTR for one landing page outperforms all others, analysts can drill down into customer attributes to check for commonalities among the customers that differs from those that didn’t convert, or those consumers diverted to different landing pages. Before pushing landing pages to larger audiences, analysts ideally want to understand why different pages outperformed others to continue optimization, and ensure that the average high performing page is not driven by weighted variability in each diverted audience segment.
At each step of the test or experiment, infrastructure provides capability that makes the practice possible: the underlying data, the ad elements in use, the platforms within which all elements function, the data processes that connect and create meaning.
Infrastructure is fundamental. Without it one can’t determine the key question or hypothesis, what should be tested, or the metric that will provide the answer.
Infrastructure Development and Deployment
The Dependencies of Infrastructure
The advantage of a broad highly-functioning infrastructure for experiments and tests is difficult to overstate. The less developed the infrastructure, the more complex, lengthy, or impractical the experiment.
- Instead of narrowing down the hypothesis with existing data supplied by early infrastructure development, marketers must expand testing to exclude additional variables.
- Instead of quickly designing and executing an experiment, marketers must decide to build necessary components (ad assets, landing pages, CTAs, etc.), or limit the design.
- Without robust data processes and platform infrastructure, analysts need to employ manual steps to aggregate and interpret data to uncover test insights.
- Without a viable and contextually complete infrastructure, experiment frameworks can not support the processes and structures that combine as a reusable test model.
More importantly, the value of the digital infrastructure exists not for tests and experiments alone. A robust end-to-end infrastructure is critical to any business offering value in the marketplace. For example, the marketing strategic plan provides building blocks for the OLA stack, but also aligns a value proposition with an unmet need, identifies the target market segments, and defines product or service attributes–all processes that increase offering value and opportunity for success.
Marketing Strategic Planning and Competitive Market Assessment
The most visible digital advertising infrastructure consists of the ad elements and the platforms that build, deliver, and track campaigns. Many marketing and ad tests focus on the digital assets of text, image, video, as well as the controlling parameters such as targeting and bidding. However, all of these components of advertising campaigns have clear precursors that originate from marketing strategic planning and market assessment, far before digital ad elements are available for optimization through tests and experiments.
Marketing strategic planning conducted prior to market entry allows businesses to define all marketing elements for creating value in the marketplace, from goal focus and segment targeting to tactics guiding all aspects of product design and delivery.
For example, strategic marketing planning defines the target market, specific segments, and general customer attributes for which an offering is designed and developed. The value proposition is conceived and tailored to connect with not only an unmet need, but to a set of values that resonate with customer segments and stakeholders: functional, psychological, financial, and beyond. Both of these strategic planning efforts provide the foundation for later ad elements, the ad targeting parameters (geographic, demographic, behavioral, etc.), and messaging (keywords, ad text, landing page) respectively.
Before launching a new market offering, or taking an existing offering to a new market, organizations gather competitive intelligence to understand their position in the market. The competitive market assessment evaluates competitors’ and the brand’s own tangible assets, providing data-driven decisioning over a broad set of marketing domains: brand awareness, digital portfolio health, search engine optimization (SEO), user experience, and various sub-domains and dimensions.
For example, a competitive assessment of site information architecture (IA) can measure visitor behavior on site pages, revealing the most effective conversion paths and the optimum placement of key elements for an ideal customer journey. Technology stack fingerprinting reveals competitive configurations of platforms and tools providing a core part of their digital advertising infrastructure. The IA insights factor into later landing page design, while the tech stack guides the brand’s website, tracking, and analytics platform configuration.
A diligent and accurate strategic marketing plan and market analysis ensures ad elements are accurate and relevant, providing the initial infrastructure, and foundation within which ad testing parameters and variances function. Omitting these steps or not pursuing them attentively precludes later attempts to optimize ads with A/B testing.
Data Science Maturity
Along with digital ad infrastructure’s tangible ad elements and the precursors they derive from, an organization’s data science level is a key measure of capability for data-driven business practices, digital advertising, and testing and experimentation. Data science domains include expected infrastructure components (architecture, platforms, tools), but are equally measured in other domains:
- Organization: awareness, people, sponsorship, strategy, culture; the skills of individual team members and the enterprise as a whole to use data to achieve goals.
- Data management: volume, sources, complexity, methodology; the breadth and depth of data management practices from managing ad delivery to, and traffic flow from multiple sources, filtering, and tracking.
- Analytics: application, practices, automated, integrated; the sophistication of analytics practices to transform advertising data into meaningful actionable information.
Data science capability is reflected in a business’s ability to use data to achieve goals. Capabilities include technical skill to connect data sources, manipulate data flows and sources to create meaningful views, track and store different elements, and use ad tracking data to create experiments. Data science maturity connects elements of the infrastructure, and increases the speed and efficiency with which data-related tasks are executed.
At the lowest functioning level of data science maturity, organizations have little data architecture, platforms, or tools, and can operate at an ad hoc level only. At this level, a company likely uses one ad platform for most digital advertising, data gathering, analytics, and testing or experimentation. The single platform defines the entire scope of advertising, ad analytics, and experimentation. Rather than identifying a need, a hypothesis, and a designed test or experiment, marketers functioning at the ad hoc level begin with tool capability, then experiment within those limits.
At the mid-level of data science maturity, organizations may manage core data science infrastructure, use a web analytics platform, multiple ad platforms, multiple methods to deliver ads and gather additional data, and more than one platform or method to analyze results. Marketers are able to conduct tests and experiments independent of an ad platform’s built-in test, and combine data sources for analytics.
At a higher level, organizations have multiple staff equipped to manage multiple ad platforms, data platforms (CRM, CDP, Marketing Automation platform, etc.), aggregate data across platforms for centralized analytics, design and execute custom experiments.
High functioning data science maturity enables the efficient use of infrastructure components to design and execute tests that would otherwise be resource prohibitive. For example, if an experiment’s hypothesis was to determine the effect of custom AI on ad delivery through the Google Ads network, a high data science maturity capability would be required: the marketing team could use custom machine learning algorithms (tested, optimized, and validated), and port the algorithm output to the delivery system using Google’s API.
A brand’s data science maturity facilitates the work, connecting elements to extract meaning through consistent structural integrity and valid data analytics. The higher a brand’s data science maturity, the easier the test and experimentation process becomes, and the more sophisticated experiments can be supported, advancing the ability to use infrastructure to its fullest innovative potential.
OLA Stack Infrastructure
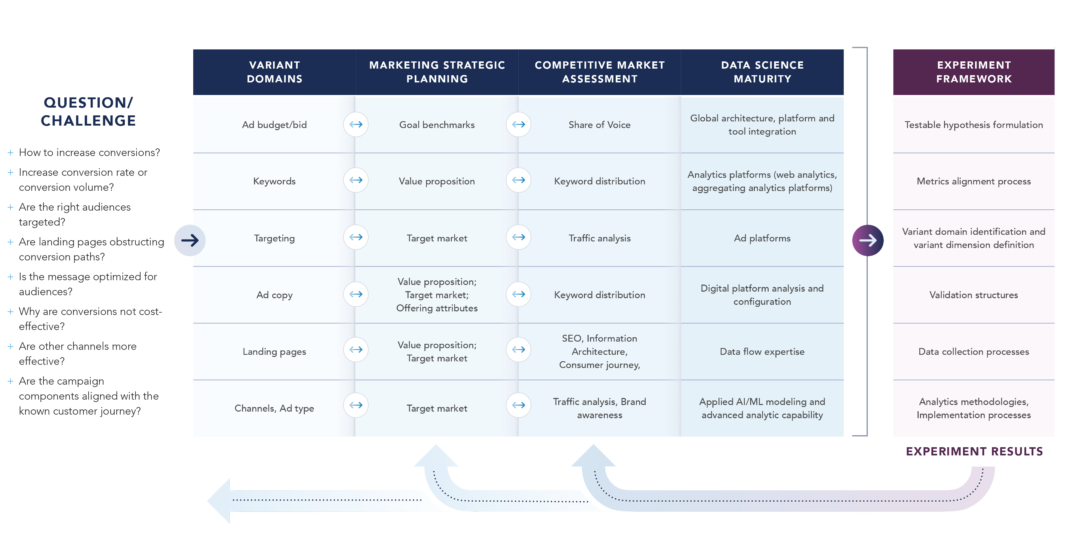
The online advertising (OLA) stack generally includes the ad budget/bid, keywords, targeting, ad copy, landing page, and the value proposition or the offer of the site. Within each are numerous dimensions which, when combined with dimensions of each OLA stack element, add to exponential variant possibilities. As these are often the primary objects of the infrastructure for ad testing and experimentation, the more thoroughly they are built out, the more opportunity exists for optimization and innovation.
Creating and maintaining the OLA stack infrastructure demands a minimum of a structured website with multiple landing pages, content aligned with validated value propositions, and data-backed personas to configure targeting parameters and to manage the messaging and creative elements.
Using strategy and market research output, a brand will create the ad objects to support multiple variances within the business model boundaries.
- Different landing pages with different CTAs, dynamic CTAs
- Dynamic LP that cycles through multiple variances with click-throughs tracked by variance
- Multiple segmenting models and combinations
- Multiple geo targets defined and configured in ad platforms
- Multiple keywords ranked
- Ad copy variants with multiple headlines, descriptions, URLs
- Multiple image variants that pair with display ad versions
- Multiple placement channels based on target segments and traffic analysis
For each domain, dimensions increase the volume and variety of ad variants, but more importantly, provide exacting precision in messaging, customer journey design, and delivery.
The development of OLA stack components is continuous and iterative as tests and experiments identify improvements and, occasionally, breakthroughs that connect with buyers to provide increased value through the brand offering.
Like testing and experimentation, strategic research and market analysis is continuous and iterative throughout each offering life cycles, and throughout the growth and development of the brand. The same infrastructure that enables competitive growth, innovative experimentation also facilitates ongoing competitive analysis that cyclically improves infrastructure and brand and customer value.
Traditional A/B or Split Testing
Traditional split tests and A/B tests are popular due to their structural simplicity, their applicability for validating a top performing variant within a small subset, and the test support built into most ad platforms.
Standard split testing relies on the OLA stack infrastructure: structured websites and multiple landing pages, ad copy aligned with value proposition, and data-backed personas to target creative work. While classic A/B testing can be used to cover hundreds of use cases, the speed of individual testing of ad parameters and combinations typically limit the depth of testing and analysis.
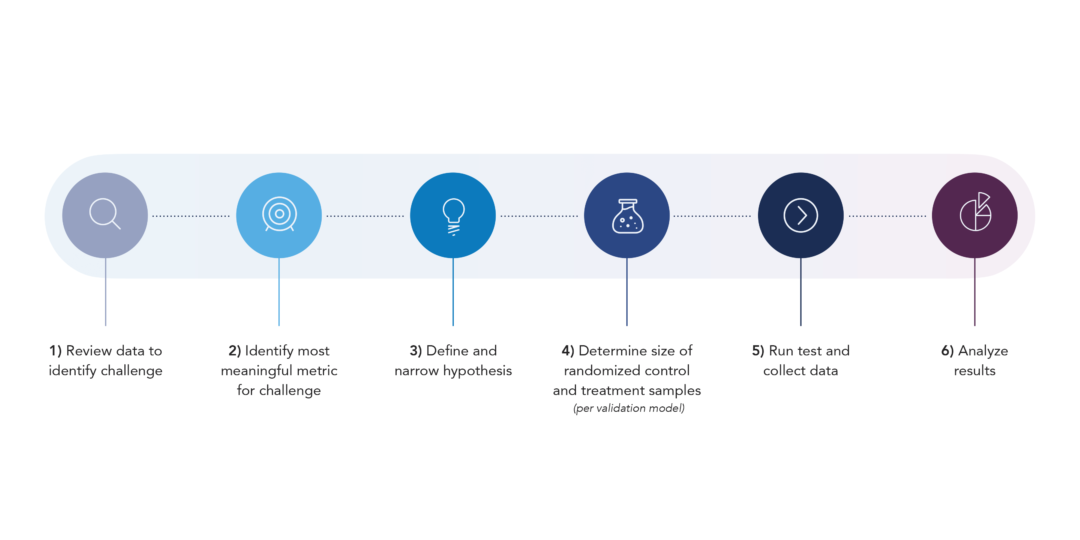
Together, these interrelated components complete a framework that allows consistent, valid, and reusable testing:
- Review data to identify challenge
- Identify most meaningful metric for challenge
- Define and narrow hypothesis
- Determine size of randomized control and treatment samples (per validation model)
- Run test and collect data
- Analyze results
- Re-test
Platform-supported A/B Tests
Many brands use their primary ad platform as the main resource for testing. Most major platforms (e.g., Google Ads, Facebook, Microsoft Ads) offer guided support for a variety of tests within the delivery platform, creating a single interface for identifying, constructing, and executing tests and experiments. Applying test results to existing campaigns or ad groups is quick and seamless. Ad platforms’ natively testing support can add significant value over manually constructed A/B tests: detailed automated tracking, automated test creation and parameter functions, and AI-driven recommendations.
Platform Independent A/B Tests
Once ad infrastructure is developed, marketers can create A/B tests regardless of the ad platform used for targeting and delivery. By employing a simple copy of campaigns, ad groups, or individual ads, and modifying the copy with the variant treatment, marketers can use the existing platform reporting to compare performance. As a result, marketing initiatives in platforms without robust built-in testing, such as Twitter or LinkedIn, can easily be tested for variant performance.
A/B tests can be effective for comparing small sets of variant options (once limited and narrowed), and can be an effective validation tool for results from broader experiments; however, A/B tests are limited when compared with potential benefits from broader, high-volume multivariate tests and experiments, particularly those paired with AI or machine learning.
Accelerators and Experimentation
A/B tests choosing between two ad variants are addressing a specific, targeted layer of testing. With thousands of variant options and parameters available, a singular focus on small split tests leaves untold opportunities unexplored. Because the volume and complexity of variables with potential to drive optimization and even breakthroughs is tremendous, businesses seeking to maximize impact employ a variety of platforms and processes to accelerate and scale these practices.
AI-Driven Platform Features
Just as most large digital ad platforms support simple A/B testing, many also include powerful ML-driven automation and optimization features that can be used to achieve results that parallel tests and experiments, improving performance that quickly scales across campaigns and audiences. While these platform-dependent features are limited in the number of domains tested and the degree of brand control, they generally outperform any corresponding manual or non-ML testing and experimentation.
AI-driven Ad Types
Google Ads offers multiple automated ad types driven by machine learning algorithms. Google’s Responsive Ads allow marketers to choose a set of assets from which the algorithm selects for best performance. For example, Responsive Search Ads automatically select from up to 15 headlines and 4 descriptions to create combinations, learn which combinations work best for different queries and serve highest performing combinations based on context. Similarly, the Responsive Display Ads will create combinations from brand-provided assets (e.g., images, copy, video, etc.) and use machine learning to serve optimal combinations based on performance. Dynamic Search Ads use a brand’s existing website content to generate ads and determine landing pages based on highest performing combinations.
Automated ad type features are not as common in smaller, niche ad platforms; however, major options such as Facebook and Microsoft Ads offer similar versions of dynamic AI-driven automated ad types.
ML-driven ad types function as a powerful form of split testing, comparing combinations of multiple ad elements to effectively test against hundreds of variants simultaneously, using automation and machine learning. As part of the ad platform, they have access to a high volume of incoming data, and can adjust variant choices based on user signals that traditional testing cannot access. For example, a visitor’s search history might include proximity to the subway, low cost, specific amenities; as a result, the algorithm will serve the ad combination that directly responds to these user signals.
While these real-time features are more powerful than A/B testing for the same optimization parameters, these features are limited compared to the full set of parameters available for testing ads. Additionally, while some ML-driven ad types allow some user parameter control, often much of the decisioning is hidden. Without knowing what combinations were served, which were successful or why, marketers may not know which parameters were effective or why.
AI-driven Bid Strategies
A less visible part of the OLA stack is the bidding parameters. Ad platforms are increasingly including automated “smart” bidding options as a way of simplifying campaign setup for advertisers, and because ML-driven bidding algorithms often rival or exceed performance of manually chosen bids. While these bidding strategies do not experiment with ad copy or similar variants, they do optimize targeting based on each strategy’s choice of metric and goal. Smart bidding for maximum conversions will broaden the target audience to achieve the greatest number of conversions, even if the conversions cost $1k each. If set to Target Cost Per Acquisition (TCPA), the algorithm will seek to get as many conversions possible at or below the target cost; as a result, the target audience choice is more focused on those most likely to convert.
Despite limitations in parameter choice and transparency, many automated and algorithm driven ad features have specific applications for mimicking test and experimentation. Compared with similar manual split tests, an ad platform’s ML-driven algorithms will usually far outperform.
Third-Party Software
Ad testing software covers a wide range of optimization-focused packages, often categorized as A/B Testing Software, Conversion Rate Optimization (CRO) Software, as well as more specialized applications for specific ad elements (e.g., ad copy, landing pages), or channel-specific testing (e.g., mobile only). Testing tools add automation, multivariate testing, and can include machine learning technology. Aligned with a specific subset of variances of brand focus, testing software can speed up testing of specific targeted parameters.
Ad and marketing test software spans across methodology, focus, and scope. Some cloud-based testing platforms integrate with ad platforms to serve different ad variants and target landing page variants while determining highest performing options. Others conduct active testing using a large base of consumer-testers to whom ads can be sent and responses captured from participants. Scope varies from software dedicated to landing pages, ad copy, or mobile only, to broad marketing research platforms that include ad testing within a suite of related applications.
Advantages
In general, the value realized by using third-party test and experiment software is dependent on a software package’s fit with a brand’s specific needs. While many tools may be barely more sophisticated than any A/B/n testing model, a small marketing group with narrow demands could gain significant advantage from the automation alone. If a marketing team has an acute but specialized need, finding a relevant, focused toolset could provide gains otherwise unlikely, while freeing up resources for advertising tasks more aligned with personnel skills.
Brands seeking to quickly add capability through a software tool should verify the domain-specific functionality most relevant, and check for more standard capabilities such as detailed results data instead of “black box” solutions, dynamic variants, automation that tracks domain and dimension variables, and integration with the necessary brand platforms (e.g., ad servers, analytics).
Many toolsets use AI to interpret performance history and predict best performing ad variants or parameters, similar to contemporary ad platforms; however with more extensive application across more varied and specific domains and dimensions. More sophisticated tools tag individual ad variant elements, allowing for a more precise level of data capture and reporting.
Limitations
The limitations of test and experimentation software are similar to many software types: package tools are likely more powerful and comprehensive than most brands need; adding another toolset to a company’s martec stack increases overall complexity; some toolsets use proprietary frameworks such as tagging, hosting requirements, effectively locking in users who choose their suite of functionality.
Some active test platforms depend on a type of forced exposure: showing ads to users and capturing their responses, whether immediate, recall, survey, or direct contact. Forced exposure measurement fails to determine whether an ad would gain the attention of consumers if embedded in a search engine results page (SERP) or on a topical website. Obtaining feedback from users required to view an ad, whether about recall, recognition, or persuasiveness, provides data points devoid of context.
The demands on the attention of today’s internet users is challenging to break through. The vast majority of US internet users now access a second screen while viewing television shows (eMarketer 2014, MetrixLab PDF). Tools designed to evaluate online ads in real environments, such as appearing in a SERP as a result of actual customer intent, are more likely to represent actual future performance.
A common approach on some broad testing and marketing research platforms is the ability to mine a brand’s existing data from the company CRM/CDP, sales data, online data, etc. The toolset’s power is dependent on the quality and breadth of the brand’s infrastructure. In the case of proprietary testing and optimization software, the brand’s assets are used while a third party is paid to pull, aggregate, and interpret their data (as long as the brand uses the software).
Automate vs Insight Gain
Tools that automate parts of the test, or that are AI-driven, provide gains in speed and optimized delivery. Many will provide a CTR boost by selecting and serving variants that perform incrementally (or substantially) better. However, providing insights into how data is used to choose or deliver variants is more critical to the progression of a brand’s test or experiment framework. Few tools provide enough detail to understand specific elements driving performance improvement. Investing in a supporting toolset for tests and experiments should move the brand’s infrastructure, methodology, and framework forward.
Custom Experiments
Effective tests and experiments can be conducted with custom frameworks that take advantage of a business’s existing infrastructure, data maturity, and internal skills to address unique hypotheses or niche business challenges. These frameworks vary from large-scale Experimentation as a Service (EaaS) platforms designed for high-volume multi-user testing to smaller custom ML solutions, applied scripting frameworks, and custom data sources connected to existing platforms. Like standard tests and experiments, the success factors for custom experiments include an infrastructure capability that matches the need.
Experimentation as a Service (EaaS)
Some digital services companies operate EaaS platforms internally to broadly encourage a culture of test and experimentation within the business, to gain tremendous return value from those experiments that prove successful, and to remain competitive.
Booking.com, a leader in online travel reservations, runs 1,000 simultaneous tests at any moment, with likely more than 25,000 tests per year. Primarily using A/B tests, the company focuses on usability and broad participation in the platform, while the experiment objects are variants from their booking website: layout, text, images, site functions, e.g., how different query responses appear, down to whether or not a hotel map shows walking paths. Each test or experiment calculates the lift of variants, implementing those with brand or consumer value.
JD.com, an e-commerce giant with over US $100B in annual revenue, developed their own digital advertising test and experiment platform for third party advertisers on their proprietary ad platform. To increase advertisers’ success, and ultimately their own, JD built a framework that prioritized advertiser ease-of-use while maintaining the goal of performance gain, in this case click-through-rates (CTR). Because a simple static A/B/n test would not provide quick gains with the complexity of media elements involved (text, images, video, landing pages), JD’s team built a randomization engine that followed individual advertiser’s goals, dynamically adapting traffic allocation away from learned poorly performing creatives. Second, new algorithms were created to handle complex target audiences and creatives at the same time, identifying best performing matches. Because they used Bayesian inference with the algorithm, advertisers could monitor experiment progress and stop and start them. The unusual user-friendly and time-saving flexibility encouraged adoption and led to real performance gains (average CTR 46% increase for all year one advertisers).
Targeted Custom Experimentation
Arcalea employs custom experimentation models to test unique hypotheses in high impact areas for our partner brands. To determine landing page variants’ ability to drive organic SERP placement, Arcalea built a multivariate ML-driven experiment.
The team identified dataset guidelines, search factor parameters, query design parameters, and the custom algorithm to run against each dataset. The resulting output identified the relative impact of each variable, effectively creating a predictive search model for the target industry.
In other cases, brands can use an existing ad platform for primary configuration of ad parameters and ad delivery, but use additional custom algorithm and parameter controls to run experiments and derive performance insights. Arcalea builds experiment frameworks external to the ad platform, then uses the platform’s API to monitor key metrics and send parameter controls. When a specified set of performance signals are received, the framework sends controls to modify ad parameters (e.g., replace ad copy, increase/decrease budget, pause keywords) based on specific performance metrics used as triggers.
Custom experiments do not dictate a costly, or large platform; instead, even small and mid-size businesses can encounter needs that are addressed with custom approaches that align with existing infrastructure and business practices.
Finding Opportunity across the Life-Cycle
No single model will respond to all the test and experiment needs of a brand. Neither can a single approach extract all the opportunities for optimization and innovation that propel a brand to long-term superior performance. Instead, businesses should use the approach, methodology, and infrastructure components that address each specific need, and identify and exploit opportunities across offering life cycles, from ideation to advocacy.
Moving Forward
The key foundation of testing and experimentation capability is a broad, contextual infrastructure. Growth-focused brands must build and update infrastructure components continuously, iteratively adding, subtracting, and improving. In addition to the OLA stack components such as ad copy, landing page, and targeting, the infrastructure includes the precursor work of strategic planning and market analysis, the data maturity level that supports the platforms, flows, connecting technologies, and analytics that together make data accessible and meaningful. Like testing and experiments, the infrastructure is also continuously and iteratively advancing with the business.
Continuous testing and experimentation for contextually relevant opportunities is both cumulative and complimentary. An experiment comparing a dozen ad copy variants across three target segments not only identifies strongest contextual performers, but also creates data insights about segment attributes and messaging that can serve as foundation for a following test or experiment. Keyword variant experiments to identify response differential for primary keyword, near synonyms with different connotations, and more specific longtail versions may provide insights that drive CTR. Complementary tests on the target landing pages ensure that visitors convert once improved keywords help get consumers there.
Getting Started
Businesses getting started with tests and experiments should focus on building capacity and using existing untapped infrastructure present within their current environment (Is an existing CRM or other platform underutilized? Is the brand website structure sound?). Build and continue to develop infrastructure. Close data maturity gaps currently obstructing necessary data flows and analytics. Start with small and simple tests, focus on opportunity present in current undertakings, and prioritize ad elements and tests based on likely scale of impact to primary goals.
Brands should take advantage of their natural infrastructure, and aim for those optimization and innovation frameworks closest to the business model, the customer profiles, and the value proposition.
Tests and experiments are required for competitive growth-focused brands, and depend on the infrastructure the company builds throughout the life cycle of each offering and through the progression of an organization’s growth and maturity. Through the use of infrastructure, data science capability, adaptable frameworks, and culture, companies can remain transformative in all business practices by continuous, iterative tests and experimentation. Brands that continuously experiment to improve the customer experience will grow and outperform those who do not make the investment.
Suggested Readings
Adalysis. Ad Testing Guide. Accessed 7/20/2021.
https://adalysis.com/scientific-ad-testing/
An excellent beginning guide to aligning metrics to test goals, with detailed breakdowns, calculations, and test application examples.
Agarwal, A., Meyer, M., O’Brien, D., Tang, D. (2010). Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Google, Inc.
Case study of Google’s search query and SERP team as they built an improved experiment framework to handle the exponential complexity of search queries using an overlapping nested layers model of dependent and independent parameters, monitored with real-time analytics.
Ascarza, Eva. (2021). Research: When A/B Testing Doesn’t Tell You the Whole Story. HBR.
https://hbr.org/2021/06/research-when-a-b-testing-doesnt-tell-you-the-whole-story
Interesting case study in which unsatisfactory results are mined for even counter-intuitive insights. The author argues that delving into customer attributes along with A/B results provides more value and avoids error.
Fan, S., Geng, T., Hao, J., Li, X., Nair, H., Xiang, B. (2021). Comparison Lift: Bandit-based Experimentation System for Online Advertising. Stanford University.
Case study of the development of EaaS advertising application currently in use on large-scale e-commerce platform, and the advanced technology required to provide an unusual customer experience for advertisers self-testing.
Kohavi, R., & Thomke, S. (2017). The Surprising Power of Online Experiments. HBR.
https://hbr.org/2017/09/the-surprising-power-of-online-experiments
Argument for the power of A/B testing when users adopt an “experiment with everything” approach; includes anecdotes of small changes validated by A/B testing that produced phenomenal returns.
Runge, Julian. (2020). Marketers Underuse Ad Experiments. That’s a Big Mistake. HBR.
https://hbr.org/2020/10/marketers-underuse-ad-experiments-thats-a-big-mistake
Kohavi and Thomke detail aversions to experimentation and methods to overcome resistance.
Thomke, Shefan H., (2020). 7 Myths of Business Experimentation. Strategy + Business.
https://www.strategy-business.com/article/Seven-myths-of-business-experimentation
Thomke outlines 7 popular arguments against experimentation as a strong mechanism for innovation, detailing the evidence against each.
Thomke, Stefan, H., (2020). Building a Culture of Experimentation. HBR.
https://hbr.org/2020/03/building-a-culture-of-experimentation
Thomke relates the experimentation efforts occurring at some large digital firms, their leaders’ journeys to achieve an experimentation culture, and the methods used to ensure innovation through experimentation became a part of their organizations
